Journal of Korean Library and Information Science Society 2025 KCI Impact Factor : 0.96
-
pISSN : 2466-2542 / eISSN : 3140-2291
- https://journal.kci.go.kr/liss
pISSN : 2466-2542 / eISSN : 3140-2291
A Study on the Development of FRBR Algorithm for KORMARC Bibliographic Record
Kim Jeong Hyen
1,
Lee Sung Sook
![]() 2,
이유정
3
2,
이유정
3
1전남대학교
2충남대학교
3영남대학교 중앙도서관 사서
1998년 IFLA에서 발표한 FRBR은 자료의 다양성과 목록의 관계성을 수용하는 이용자 지향적 모형으로서 이미 전 세계 목록의 이론적 바탕이 되고 있다. 각국의 서지기관에서는 이러한 추세를 반영하여 기존의 서지레코드를 대상으로 FRBR을 기반으로 한 새로운 구조화를 시도하고 있다. 그런데 FRBR을 적용하여 실제로 목록을 구조화하기 위해서는 FRBR을 적용한 알고리즘 개발이 선행되지 않으면 방대한 서지레코드를 대상으로 관련 저작을 유형별로 군집화 하는 것이 거의 불가능하다.
기존의 서지레코드에 FRBR을 적용하여 관련 서지레코드를 유형별로 군집화 한다는 것은 MARC 등 다른 입력 형식으로 이미 편목되어진 서지레코드를 FRBR 개체로 재분해하는 과정이라고 볼 수 있다. 즉 기존의 서지레코드를 FRBR 모형의 관점으로 분해하여 저작 수준으로 모으고, 모아진 레코드를 표현형, 구현형, 개별자료 수준으로 각각 구분하는 것이다. 이러한 FRBR화 과정은 수작업으로 구현하는 것은 거의 불가능하기 때문에 컴퓨터 알고리즘을 통해 자동화를 통해 이뤄진다. FRBR 모형이 발표되고 서지레코드에 실제적으로 적용하기 위한 과정에서 FRBR화를 위한 알고리즘 개발에 대한 논의가 OCLC나 LC 등을 중심으로 다수 진행되었다.
KORMARC 서지레코드에 있어서도 FRBR과 관련된 많은 연구가 있으나, FRBR 알고리즘을 개발하여 자료검색에 적용하기 위해서는 실제로 프로그램을 개발하여 직접 서지데이터베이스에 적용하여 봄으로서 문제점을 분석한 실제적인 연구가 필요하다. 아울러 FRBR의 저작 유형은 물론, 각종 자료유형별로 KORMARC 서지레코드의 특성을 분석하여 알고리즘에 반영해야 한다.
이 연구의 목적은 KORMARC 서지레코드를 유형별로 분석하여 FRBR을 적용한 검색 알고리즘을 개발한 후, 실제로 검색 과정을 국립중앙도서관의 KORMARC 서지데이터베스를 통해 직접 실험하여 봄으로써 KORMARC 서지레코드의 FRBR 적용을 위한 기초자료를 제시하는데 있다.
이 연구의 구체적인 대상과 방법은 아래와 같다.
첫째, 국립중앙도서관 소장 문학류(1910~2013년 발행) 단행본 약 20만 건을 실험대상으로 한다. 문학류가 다양한 서지적 관계유형을 가장 많이 포함하고 있는 것으로 알려져 있어 이를 실험대상으로 하였다. 단행본으로 한정하였지만 단행본에서 파생된 다양한 유형의 자료도 검색 알고리즘에는 포함될 수 있도록 설계한다.
둘째, KORMARC 서지레코드에 내포된 다양한 서지적 관계 유형을 FRBR 모형에 적용하여 검색에 반영하는 알고리즘을 설계한다.
셋째, FRBR 모형을 적용한 자료 검색 알고리즘 설계는 아래와 같은 순서로 연구를 진행한다.
① 알고리즘 설계관련 국내외 사례 분석을 한다. 특히 이 연구와 관련이 높은 OCLC와 LC 등에서 개발한 FRBR 알고리즘을 중점적으로 분석한다.
② FRBR 알고리즘 사례 분석을 바탕으로 국립중앙도서관의 서지레코드를 문학 장르와 서지유형별로 분석하여 FRBR 모형을 적용한 알고리즘을 설계한다.
③ 국립중앙도서관의 문학류 서지레코드 가운데 가능하면 다양한 저작유형을 반영할 수 있는 사례들을 엄선하여 실험 데이터로 사용한다.
④ 알고리즘 설계내용을 바탕으로 유형별로 엄선한 실험 데이터를 직접 적용해봄으로써 FRBR 모형 적용과 관련된 문제점을 분석한다.
FRBR이 발표된 후 기존의 서지레코드를 대상으로 기계적 변환을 통해 FRBR을 적용하려는 논의 와 함께 실제로 알고리즘이 개발되기도 하였다. 이 가운데 대표적인 사례로 저작 수준의 개체를 군집화한 OCLC의 FRBR Work-Set Algorithm을 들 수 있으며
또한
한편 KORMARC 데이터를 분석대상으로 한 연구는 아래와 같다. 먼저
지금까지 살펴본 바와 같이 FRBR 알고리즘의 개발은 OCLC와 LC가 선도하고 있으며, 이를 바탕으로 각국에서 적용 실험이 이루어지고 있다. KORMARC의 경우에도 다양한 연구가 이루어지고 있으나 실제적인 적용에 이르지 않고 실험적인 연구에 머무르고 있다.
앞절에서 살펴본 바와 같이 FRBR 알고리즘은 주로 OCLC와 LC를 중심으로 개발되고 있으며, 이것은 MARC 21의 서지레코드를 대상으로 하고 있어 KORMARC과 유사성이 있다. 따라서 여기서는 OCLC와 LC의 알고리즘 및 KORMARC을 중심으로 분석하고 있는 국내의 FRBR 알고리즘 관련 연구를 중심으로 보다 자세하게 살펴보기로 한다.
우선 OCLC의 알고리즘은 매칭정보로 전거와 서지레코드의 이름과 표제 관련 표목을 사용 하는데, 구체적으로는 전거레코드로부터 표목[이름+표제(혹은 이름) 대표형과 변형]를 자동 생성하고, 서지레코드에서 ‘저자명+표제’를 추출하여, 전거레코드의 표목[이름+표제(혹은 이름) 대표형과 변형]전거와 서지레코드의 ‘이름+표제 관련 표목’을 매칭한다. 매칭된 서지 레코드의 대표 엔트리로는 전거레코드의 ‘이름+표제’ 또는 ‘이름 또는 통일표제’ 중 적절한 대표형을 저작의 대표키로 할당한다. 반면 LC의 알고리즘은 ‘이름 또는 표제’로 검색한 결과로 출력되는 서지레코드를 대상으로 FRBR 알고리즘을 적용하며, 매칭정보로 서지레코드의 ‘저자+표제’ 또는 ‘표제’를 추출한 후 서지레코드끼리 매칭한다. 대표 엔트리로는 서지레코드의 저자, 표제 대표키를 할당한다.
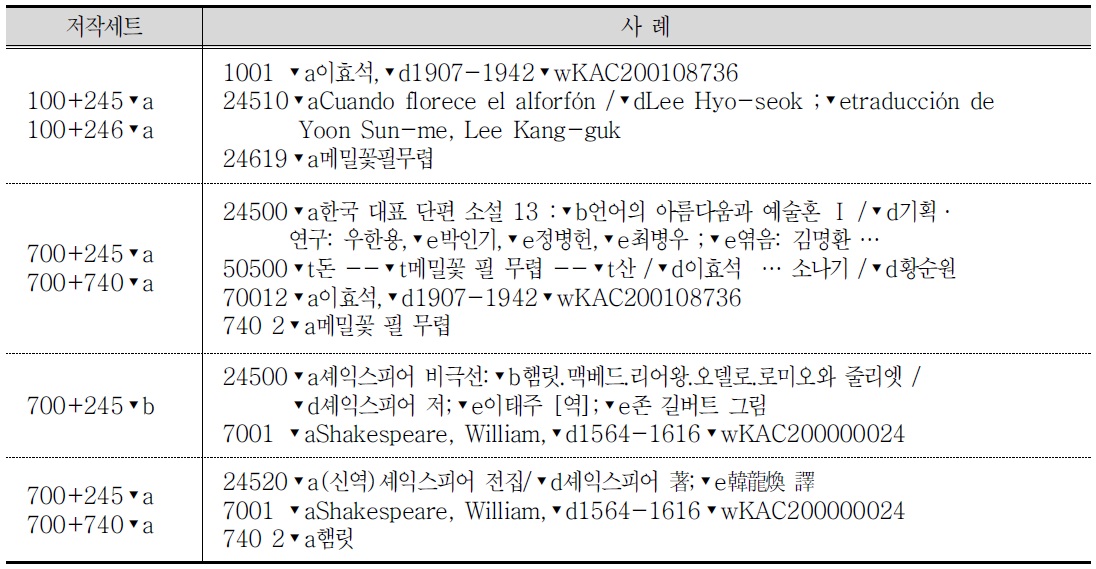
이어서 기존의 FRBR 알고리즘에서 사용된 저작 수준의 대표키 생성과 표현형, 구현형, 개별자료 수준에서의 식별요소를 비교 분석하면 아래와 같다.
첫째, 저작 대표키 조합의 방법에 있어 알고리즘마다 사용하는 표현방법이나 사용하는 표시기호나 식별기호, 우선순위 등의 차이가 있지만, 대체로 아래와 같다. OCLC의 알고리즘은 ① 저자(1XX 필드)가 있는 경우, ② 통일표제 사용, ③ 저자(1XX 필드)가 없는 경우, ④ 표제+OCLC번호의 기타방법 등을 언급하고 있다. LC의 알고리즘은 1XX 필드가 있는 경우와 없는 경우로 구분하고 있으며, OCLC와 달리 1XX 필드 없을 때 7XX 필드를 사용하지 않는다. LC에서는 이름 또는 표제로 검색한 결과로 출력되는 서지레코드를 대상으로 FRBR 알고리즘을 적용하기 때문에 표제만으로 저작 대표키를 사용하고 있다.
둘째, 저작 대표키의 한 부분인 저자키 생성과 관련하여, LC는 1XX 필드만, 나머지 선행연구에서는 7XX 필드도 포함하고 있다. OCLC는 1XX와 7XX 필드가 연결된 880 필드를, 노지현은 900 필드를 포함시키고 있다.
셋째, 저작 대표키의 또 다른 부분인 표제키 생성과 관련하여 LC는 1XX 필드가 있는 경우와 없는 경우로, OCLC는 표제를 단축표제와 완전표제로 구분하여 제시하고 있다. 노르웨이 국립도서관에서는 500, 505 필드를 포함하고 있다. 국내 연구자의 경우 240/245/740 필드의 ▾a를 포함하고 있으며, 조재인은 505과 730 필드, 이미화는 507(분석대상이 USMARC 기반인 H대학을 이므로) 필드를 포함시키고 있고, 김현희는 LC와 유사하게 각 필드의 식별 기호를 포함하고 있다. 통일표제에 대해서는 공통으로 130 필드를 언급하고 있다.
넷째, 동일한 저작으로 묶인 서지레코드의 표현형 식별요소는 OCLC는 언어(008 필드 /35-37), LC는 언어에 자료유형(리더/06)을 언급하고 있다. 국내의 경우 OCLC나 LC가 언급한 식별기준이외에 노지현은 언어에 130과 240 필드의 ▾l, 자료유형에는 008 필드/23을 추가하였고, 이용대상자 수준(008 필드/22)을 추가하였다. 이미화는 250▾a(숫자만 추출) 를 추가하였다. 김현희는 연구대상자료가 음악자료임을 감안하여 546▾a와 245▾h, 254▾ a, 511▾a, 518▾a를 추가하였다.
다섯째, 구현형에 대해 OCLC, 조재인, 이미화의 연구에서는 군집화를 수행하지 않았다. LC에서도 이 수준에서는 군집화를 수행하지 않았다. 다만 구현형 수준에서는 발행년도(008 필드/07-10)로 정렬하며, 디스플레이를 위해 판사항(250▾ab), 표제(245▾abnp), 저작책 임(245▾c), 출판사항(260▾bcg), 형태사항(300), ISBN(020▾acz), ISSN(022▾ayz), 출판사번호(028▾ab), CODEN(030▾az), 복제(533) 등을 제안하고 있다. 개별자료에 대해서는 국립중앙도서관과 노지현의 연구에서만 구현형에 대한 복본표시와 소장자료를 제시하는 수준의 작업을 수행함이 언급되어 있다.
FRBR의 구현을 위한 설계 내용은 아래와 같다.
첫째, FRBR은 제1집단의 서지적 개체를 크게 저작, 표현형, 구현형, 개별자료의 4가지로 구분하고 있다. 이 연구에서도 이러한 4가지 개체로 구분하여 알고리즘을 개발하기로 한다.
둘째, FRBR의 핵심은 특정 저작의 모든 관련 저작을 유형별로 제시하는데 있다. 그러기 위해서는 관련 저작을 묶을 수 있는 연결 고리가 필요하며, FRBR을 기반으로 하고 있는 RDA에서는 저작의 전거형 접근점을 사용하고 있다(RDA 6.27). 이 연구에서도 RDA에서와 같이 저작의 전거형 접근점을 작성하여 관련저작을 모을 수 있도록 ‘저자+표제’(저자가 없는 경우 ‘표 제’)와 같은 저작의 전거형 접근점을 작성할 수 있는 알고리즘이 설계될 수 있도록 한다.
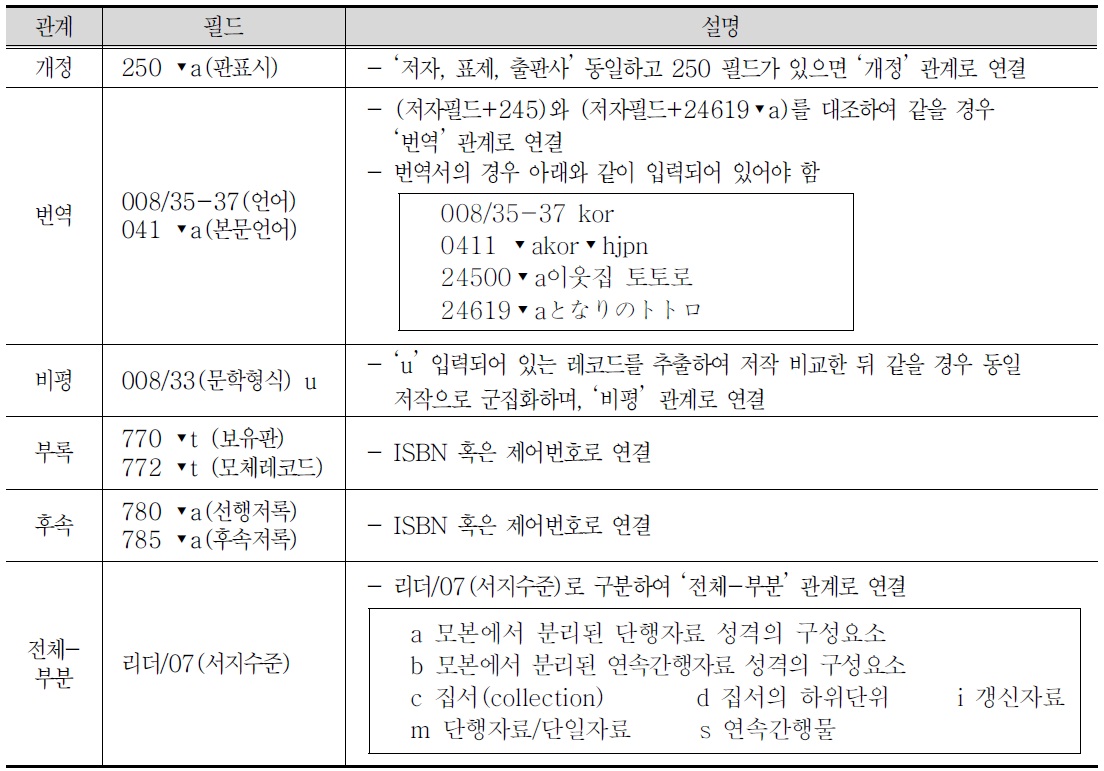
셋째, 개정, 번역, 비평 등 서지적 관계를 표현하는 필드를 추출하여 알고리즘에 반영한다.
넷째, 표제의 추출을 위해 표제 관련 필드(240, 245, 246, 740) 외에 내용주기 필드 (505)에 포함된 표제도 추출하도록 하여 알고리즘을 개발한다.
알고리즘 설계 과정에서 다양한 경우의 수가 포함될 수 있도록 다양한 서지유형과 문학 장르가 포함된 실험데이터를 선정하였으며, 문학 작품의 경우 비교적 널리 알려진 작품을 대상으로 하였다.
문학 이론서의 경우 초판과 개정판 등이 동시에 있는 자료를 선정하였다. 문학 작품의 경우 소설, 시, 희곡의 문학 장르를 포함하여 언어, 출판사항, 자료 유형(도서, 녹음자료, 시청각자료, 장애인대체자료 등)이 다양하며, 이러한 사항이 골고루 포함된 자료를 선정하였다. 한국소설에는 고대소설, 장편소설, 단편소설이 골고루 포함되도록 하였으며, 한국 시의 경우 서지레코드가 많으면서 한국어 외에 다른 언어로 번역된 작품이 포함된 자료를 선정하였다. 외국문학의 경우 희곡, 소설 등 문학 작품의 번역서를 포함하였다. 한국소설과 외국 번역자품의 경우 관련 서지레코드가 적어도 100건 이상인 자료를 선정함으로써 다양한 관련 서지레코드의 사례가 포함될 수 있도록 하였다. 무저자 고전인 『춘향전』을 포함하여
<표 1>. FRBR 알고리즘의 실험데이터 리스트
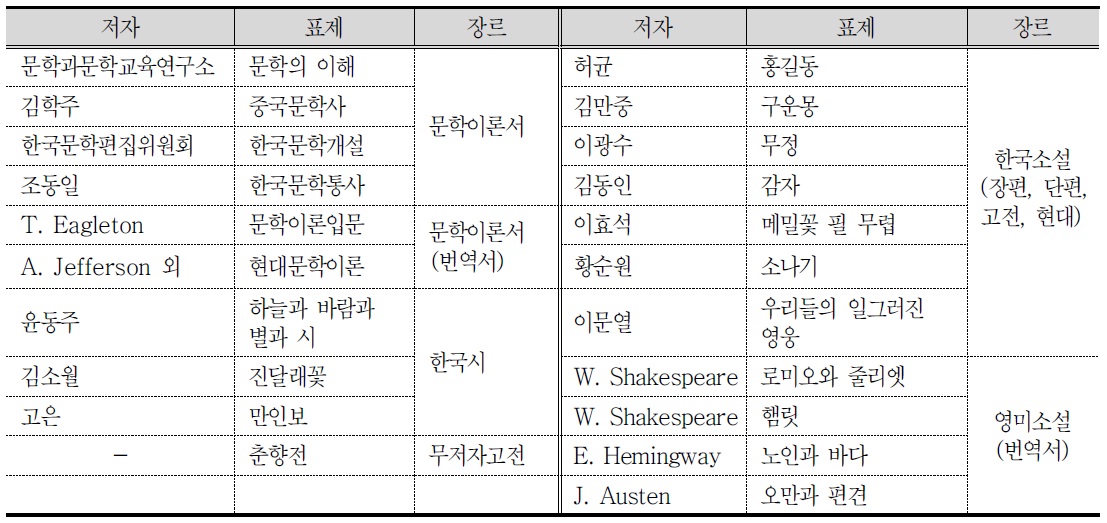
저작은
표제의 경우 표제 필드인 240, 245, 246▾a를 우선 추출한 다음 740▾a를 추출하며, 표제 필드의 개수에 상관없이 모든 표제가 추출될 때까지 반복 실행한다. 표제 추출을 위한 식별기호로는 ▾a뿐만 아니라, ▾n▾p▾x를 모두 사용한다. 예를 들면, “24500▾a이문열 중단 편전집/▾d이문열 지음.▾n4:▾p우리들의 일그러진 영웅 외”나 “24510▾aCielo, viento, estrellas y poes'ia=▾x하늘과 바람과 별과 詩 /▾dYun Tong-Ju”에서 “▾p우리들의 일그 러진 영웅”과 “▾x하늘과 바람과 별과 詩”를 모두 표제로 추출한다.
합집이나 선집 레코드에서 표제를 추출할 때, 245 필드에 기술된 합집 표제뿐만 아니라 합집에 포함된 개별 표제도 추출한다. 505 필드의 내용주기에 개별 저작을 기술한 경우 개별 저작에 대한 740 필드를 사용하고 부출 표제가 없는 경우 내용주기에 포함된 ▾t 표제를 사용한다.
<표 2>. 저작세트 추출의 사례
저자명없이 표제만 있는 경우
<표 3>. 표제 추출(무저자)의 사례

<표 4>. 표제 추출(무저자-통일표제)의 사례

표현형 식별을 위해
<표 5>. 표현형(번역)의 사례

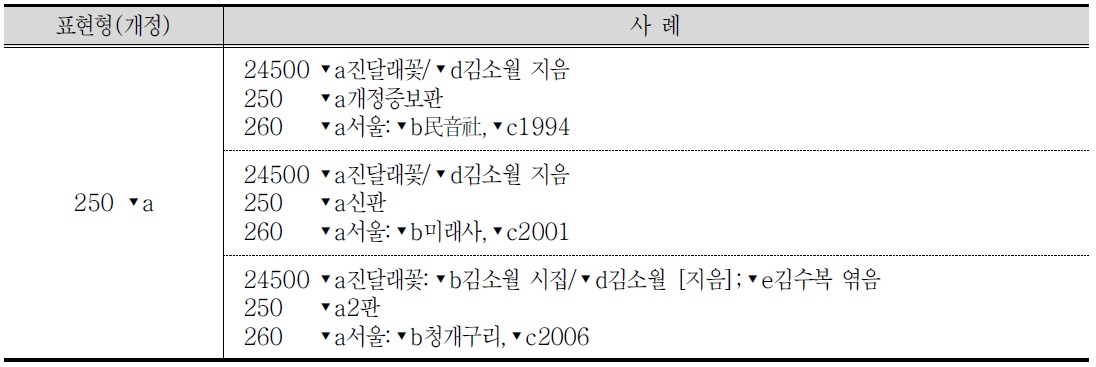
동일 저작에서 판사항은 표현형의 식별요소로 사용한다.
<표 6>. 표현형(개정)의 사례
문학작품에 대한 비평서를 식별하기 위해 008 필드/33(문학형식)에 u(평론)가 입력되어 있는 것은 비평으로 사용한다.
모체레코드와 보유판 및 특별호의 관계를 연결하기 위해 770과 772 필드를 사용한다. 이때 모체와 보유판의 연결은 ISBN이나 제어번호로 연결한다.
선행 저록과 후속 저록을 연결하기 위해 780과 785 필드를 사용한다. 이때 선행저록과 후속저록의 연결은 ISBN이나 제어번호를 사용한다.
구현형은 군집화된 저작과 표현형을 적절한 형식에 맞추어 디스플레이 한다.
다양한 자료유형을 디스플레이하기 위해 245 필드의 ▾h를 사용한다. 자료유형표시가 없는 것은 단행본이며 자료유형표시가 없는 자료 중 502 필드가 있는 것은 학위논문에 해당한다. 자료유형표시가 있는 것은 ‘녹음자료’, ‘컴퓨터파일’, ‘비디오 녹화자료’ 등 해당 자료유형을 표기한다. 그런데 RDA에서는 자료유형을 보다 세분하여 내용유형, 매체유형, 수록매체유형의 3가지로 구분하여 표시하고 있다. 또한 KORMARC에서도 이를 반영하여 336, 337, 338 필드를 사용하여 표시할 수 있도록 개정되었다. 앞으로는 이 가운데 구현형 식별 요소인 337과 338 필드를 사용하여 자료유형을 디스플레이 하는데 사용할 수 있다.
원자료에 대한 복제를 추출하기 위해 534, 580, 776 필드의 유무를 확인하여 원자료와 복제자료를 연결한다.
250 필드에 재판 혹은 중판으로 입력된 데이터로 동일 저작인 경우 재판의 관계로 연결한다. 250 필드가 입력되어 있지 않지만 저자와 표제, 출판사가 동일한 자료가운데 출판연도나 페이지가 상이한 경우 쇄의 개념으로 취급하여 구현형의 다른 형태로 표기한다.
개별자료의 사례로는 국립중앙도서관 청구기호 052 필드와 등록번호 및 복본표시 049 필드에 입력된 내용으로 확인한다.
FRBR 적용 검색 알고리즘의 흐름을 FRBR의 저작, 표현형, 구현형, 개별자료의 수준별로 살펴보면
<그림 1>. FRBR 적용 검색 알고리즘 흐름도
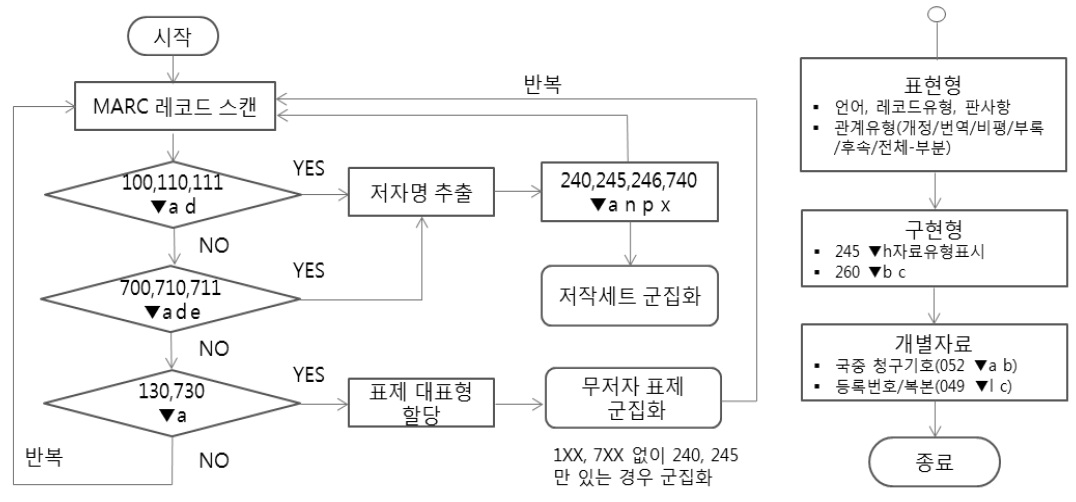
현재 국립중앙도서관 검색키에는 전체, 제목, 제목(전방), 제목(완전), 저자, 발행자, 청구 기호로 구성되어 있으며, 이 연구에서는 전체, 표제, 저자, 발행자를 검색키로 선정하였다.
저작의 군집화를 위해 저자와 표제의 요소 추출은
<표 7>. 저작(저자와 표제) 추출 기준
자료유형에 해당하는 요소를 추출하기 위해 레코드 유형(리더/06)의 값을 사용한다. 일반 적인 도서형태는 a(문자자료)로 구분하며 ‘a’가 아닌 전자자료, 녹음자료, 시청각자료 등은 해당 유형의 값으로 자료유형을 구분한다. 기존의 KORMARC 서지레코드에는 자료유형표시를 245 필드의 ▾h에 기술하고 있으나 여기에는 표현형 요소와 구현형 요소가 혼재되어 있다. RDA에서는 이를 세분하여 표현형 요소인 내용유형, 구현형 요소인 매체유형과 수록매체 유형으로 구분하고 있으며, KORMARC도 이를 반영하여 최근에 수정되어 있다. 즉, 앞으로는 RDA의 내용유형을 구조화한 336 필드를 사용하여 표현형 요소를 추출할 수 있다.
이용대상자 수준을 구분하기 위해 008 필드/22의 값을 사용하며, 일반이용자( b/) , 청소년 (b, c, d), 아동(j), 특수계층(f)으로 범주화한다.
문학 장르를 표기하기 위해 008 필드/33의 값을 사용하며, 평론(u)의 경우 비평의 관계를 표현하기 위해 사용한다.
개정, 번역, 비평, 부록, 후속, 전체-부분 등과 같은 서지적 관계유형은 대체로 표현형 수준에서 식별한다. 이러한 서지적 관계유형을 식별하기 위한 요소 값은
<표 8>. 표현형(관계유형) 요소
구현형 식별을 위한 추출 요소는 아래와 같이 자료유형, 발행처 및 발행년, 관계유형 등이다.
기존의 KORMARC 서지레코드에는 자료유형표시를 245 필드의 ▾h에 기술하고 있어 이를 구현형 식별 요소로 사용할 수 있지만, 앞으로는 RDA에서 제시하고 있는 내용유형, 매체 유형, 수록매체유형의 3가지가운데 매체유형과 수록매체유형을 구현형 식별 요소로 사용할 수 있다. 즉, KORMARC 서지레코드에 RDA를 반영한 337과 338 필드를 사용하여 구현형 요소를 추출할 수 있다.
발행처 및 발행년은 260 필드의 ▾b▾c에 기술하고 있어 이를 구현형 식별 요소로 사용한다.
구현형에서 관계유형은
<표 9>. 구현형(관계유형) 요소

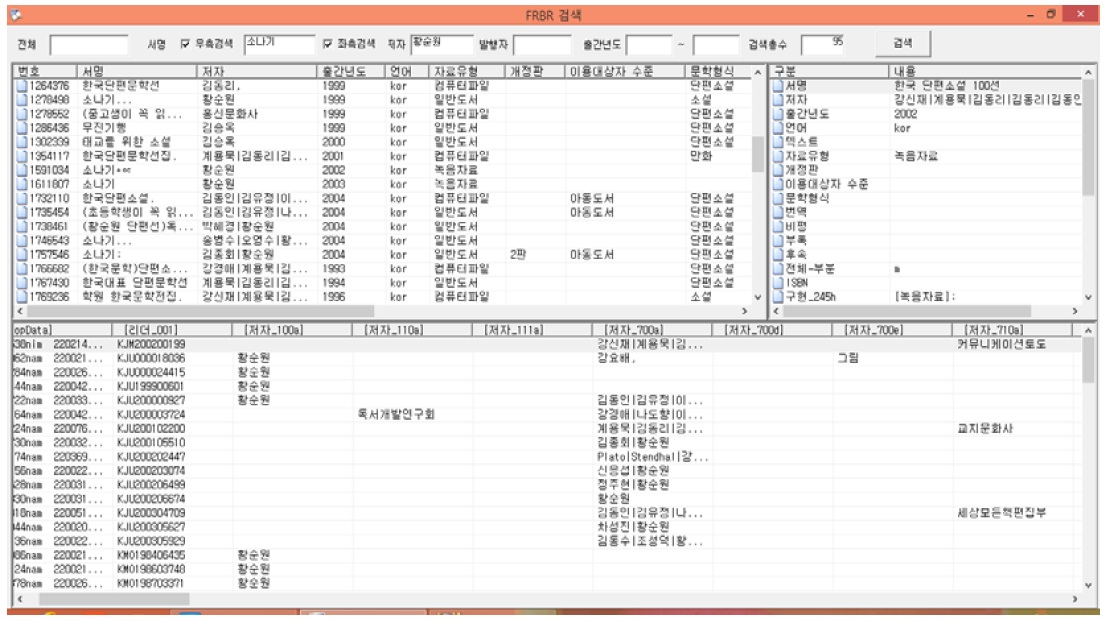
앞서 설계된 FRBR 적용 검색 알고리즘을 구현하여 추출된 레코드의 수는
<그림 2>. 저작세트(소나기+황순원)의 추출
<표 10>. 저작세트(소나기+황순원)의 검색 내용
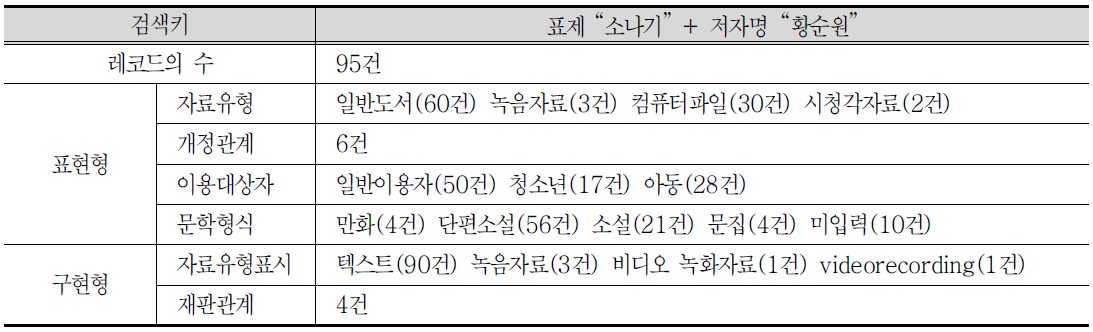
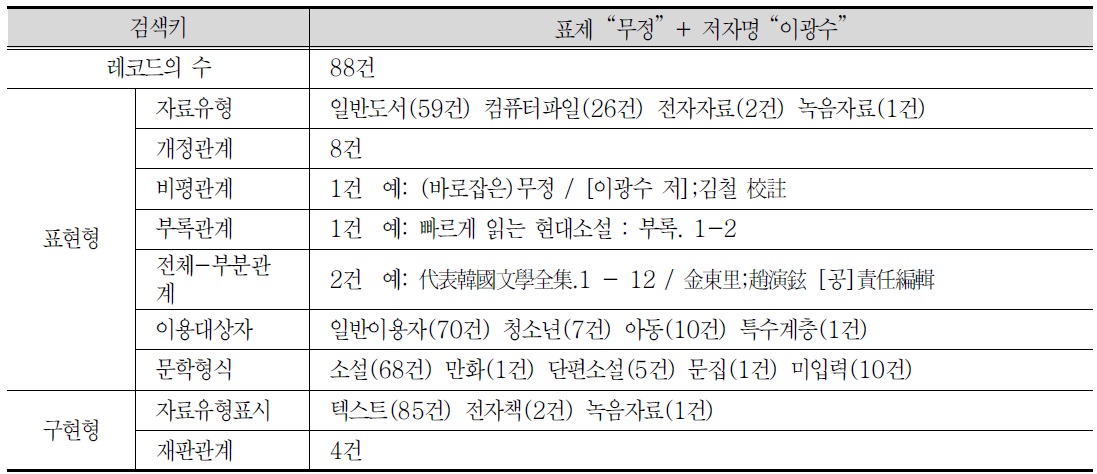
레코드의 수는 88건이 추출되었으며, 분석결과 표현형과 구현형은
<표 11>. 저작세트(무정+이광수)의 검색 내용
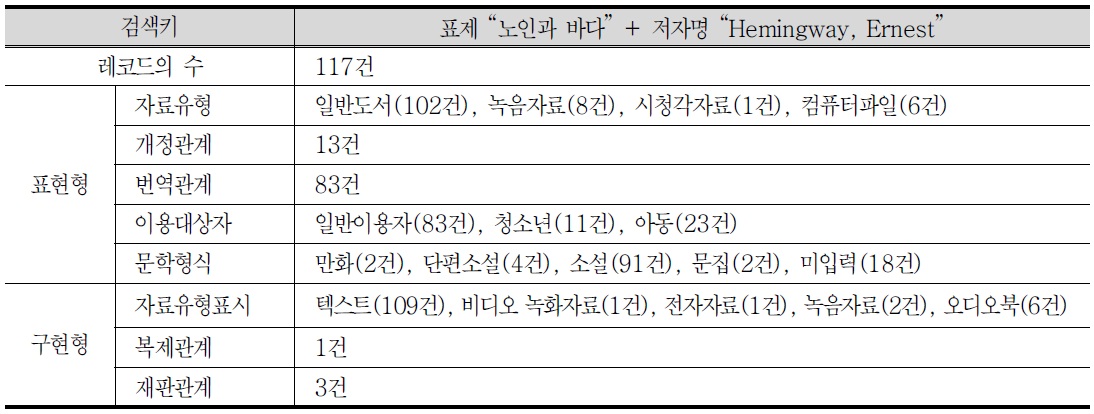
레코드의 수는 117건이 추출되었으며, 분석결과 표현형과 구현형은
<표 12>. 저작세트(노인과 바다+Hemingway, Ernest)의 검색 내용
레코드의 수는 82건이 추출되었으며, 분석결과 표현형과 구현형은
<표 13>. 저작세트(노인과 바다+Hemingway, Ernest)의 검색 내용

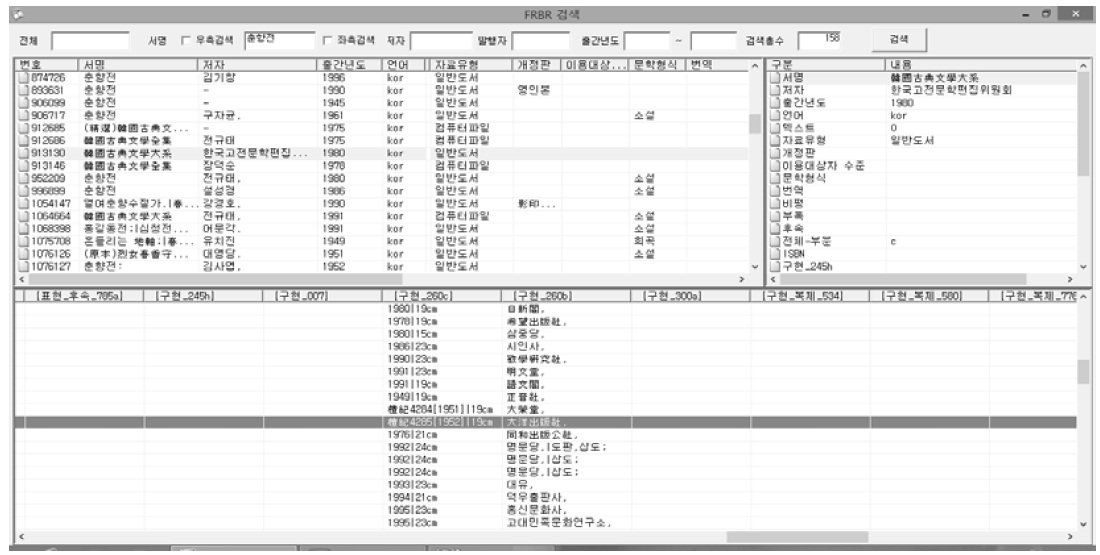
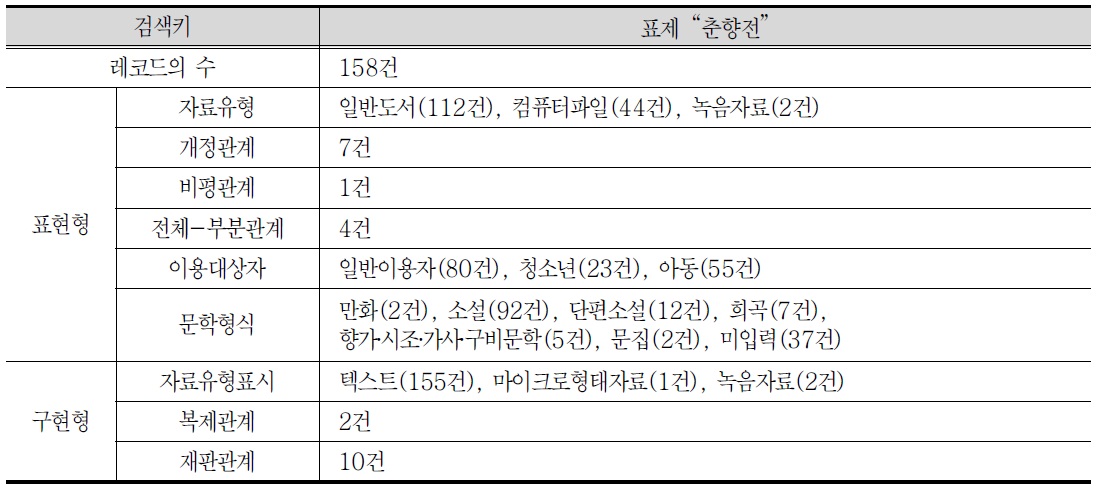
『춘향전』의 레코드 수는
<그림 3>. 저작세트(춘향전)의 추출
<표 14>. 저작세트(춘향전)의 검색 내용
앞서 언급한 바와 같이 이 연구에서 알고리즘 설계를 위해 실험데이터를 연구의 목적에 맞게 유형별로 선정해서 분석하였으며, 분석한 결과를 알고리즘 개발에 반영하였다는 점에서 기존 연구와 차이점이 있다고 할 수 있다. 설계된 FRBR 알고리즘의 특징을 살펴보면 아래와 같다.
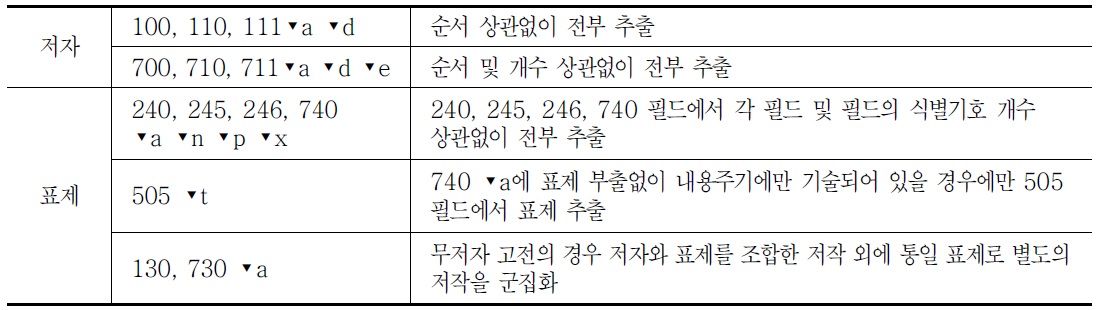
첫째, 저작은 ‘저자명+표제’로 구성되는데, 저자명 생성과 관련하여 1XX 필드뿐만 아니라 7XX 필드의 ▾a d e를 대상으로, 표제의 경우 240, 245, 246, 740 필드의 ▾a n p x를 대상으로, 통일표제의 경우 130과 730 필드의 ▾a를 대상으로 추출하였다. 합집이나 선집에서 740 필드의 표제부출없이 내용주기에만 기술되어 있는 경우 505 필드도 활용하였다.
둘째, 표현형의 요소로는 자료유형(리더/06), 이용대상자수준(008/22)을 사용하였다. 표현형의 요소뿐만 아니라 표현형의 관계유형 요소도 추출하여 활용하였다. 표현형의 관계유형 요소로 개정(250▾a), 번역(008/35-37, 041▾a), 비평(008/33 u), 부록(770, 772▾t), 후속(780▾a), 전체-부분(리더/07)을 추출하였다.
셋째, 구현형의 요소로는 자료유형표시(245▾h), 발행처 및 발행년(260▾b c)을 사용하였으며, 구현형도 요소뿐만 아니라 관계유형 요소를 추출하여 활용하였다. 구현형의 관계유형 요소로 복제(534, 580, 776), 재판(250▾a 중판, 재판)을 추출하였다.
그런데 KORMARC 서지레코드에 있어 FRBR 적용을 위한 알고리즘을 보다 효과적으로 달성하기 위해 몇 가지 사항을 제안하면 아래와 같다.
첫째, FRBR 적용을 위해서는 RDA에서 중요시하는 바와 같이 전거형 접근점의 작성을 강화할 필요가 있다. 인명전거의 중요성은 국내 도서관계에서도 오래전부터부터 인식하고 나름대로 작성을 하여오고 있었지만, 표제전거는 대부분의 도서관에서 간과되어 왔던 것이 사실이다. 통일표제라는 이름으로 표제전거가 이루어지고 있었지만 실제 도서관 현장에서는 매우 제한적으로 이루어지고 있을 뿐이다. 특히 국내 고전작품의 표제전거를 위한 추가적인 작업이 필요하다고 생각된다.
둘째, 역할어나 연관저록 등의 입력 요소를 강화할 필요가 있다. 지금까지는 번역자, 삽화가, 편역자, 감독자 등과 같은 역할어나 연관저록 등의 요소가 검색에서 그다지 활용되지 않은 관계로 대부분의 도서관에서 실제 목록작업에 있어서도 생략되는 경우가 많았다. 그렇지만 FRBR 및 RDA에서는 자료 식별을 위한 활용을 고려하여 이러한 요소들을 강화하는 경향이 있다. 특히 구현형의 표현이 기계적 알고리즘으로 유연하게 이루어지기 위해서는 요약, 개작, 변형, 비평과 같은 서지적 관계유형도 일반주기보다는 연관저록으로 기술될 수 있도록 확대하는 방안을 고려해 볼 수 있다.
셋째, 저작세트를 구성하여 검색한 결과 특히 구현형 수준에서 검색되어야 할 상당수의 자료, 예를 들면, 온라인자료(전자책, 원문 등)와 디지털화하여 서비스하는 소장원문자료 등은 실제로는 MODS로 구조화되어 있다. 이 연구의 알고리즘은 MARC 기반이며, MODS를 기반으로 한 레코드에 대해서도 통합할 수 있는 추가적인 연구가 필요하다고 생각된다.
넷째, FRBR의 적용효과가 가장 높다고 기대되는 문학류를 대상으로 알고리즘을 개발하였다. 이를 활용할 시에도 OCLC와 같이 문학에 한정하여 일정기간 시행과정을 거친 후, 효과성이 높을 것으로 예상되는 분야에 대해 단계적으로 검토해야 할 것이다.
다섯째, 국제목록원칙규범의 기본이 되고 있는 이용자 편의성을 달성하기 위해서는 어떠한 요소를 입력하느냐, 얼마만큼 입력했느냐에 달려 있다. FRBR 알고리즘도 제대로 기능을 하기 위해서는 기본적으로 원래의 레코드 제대로 작성되어 있어야 한다. KORMARC 입력 데이터의 수준을 분석한 결과 현행 목록 데이터로는 FRBR을 위한 저작과 표현형을 구분하기 어렵고, 전거나 서지적 관계요소 등이 생략되어 있는 경우가 많다. FRBR를 적용하기 위해 기존의 레코드입력 수준을 전반적으로 강화할 필요가 있다.
KORMARC 서지레코드의 FRBR 적용 알고리즘을 개발하여 문학류를 대상으로 실험한 결과, 기존의 검색 프로그램에 비해 관련 자료를 보다 망라적이고 체계적으로 제시할 수 있었다. 알고리즘의 설계내용과 함께, 연구결과를 요약하면 아래와 같다.
첫째, OCLC의 FRBR Work-Set Algorithm과 LC의 FRBR Display Tool Version 2.0 등을 비롯한 국내외 FRBR 구현 알고리즘 개발 사례의 장단점을 비교 분석하여 이 연구의 기반으로 활용하였다.
둘째, FRBR에서 구분하고 있는 저작 유형에 따라 저작, 표현형, 구현형, 개별자료의 4가지로 구분하여 알고리즘을 개발하였다.
셋째, 국립중앙도서관의 국가서지레코드에서 추출한 실험데이터를 분석하여 저작, 표현형, 구현형, 개별자료의 식별요소를 분석하였다. 저작 식별요소로 ‘저자+표제’, 표현형 식별요소로 번역, 개정, 비평, 모체-부록, 선행-후속, 구현형 식별요소로 자료유형, 복제, 제판 또는 중판, 개별자료 식별요소로 청구기호, 등록번호, 복본기호를 선정하였으며, 여기에 해당하는 KORMARC 요소를 분석하여 제시하였다.
넷째, 저작세트별로 관련 저작을 군집화하기 위해 RDA에서 저작세트를 군집화하기 위한 기본 장치로 적용하고 있는 전거형 접근점을 사용하였으며, ‘저자+표제’와 같은 전거형 접근 점을 작성할 수 있는 알고리즘을 설계하였다.
한편 FRBR 알고리즘을 개발하면서 국가서지레코드를 분석한 결과, KORMARC 서지레코드를 대상으로 FRBR 알고리즘을 적용하기 위해서는 기존의 서지레코드를 정비하고 레코드의 입력 수준을 전반적으로 강화할 필요가 있다.
1.
[book]
2007
2.
[journal]
김, 정현.
2007
![]()
3.
[journal]
김, 정현.
2007
![]()
4.
[journal]
김, 현희, 유, 영준, 박, 서은.
2007
![]()
5.
[journal]
노, 지현.
2008
![]()
6.
[thesis]
이, 미화.
2008
7.
[thesis]
이, 성숙.
2004
8.
[journal]
이, 성숙.
2006
![]()
9.
[journal]
이, 유정.
2007
![]()
10.
[journal]
조, 재인.
2004
![]()
11.
[journal]
조, 재인.
2005
![]()
12.
[journal]
2009
13.
[journal]
2008
14.
[journal]
Aalberg, Trond.
2006
“A Process and Tool for the Conversion of MARC Records to a Normalized FRBR Implementation.”
15.
[journal]
Aalberg, Trond, Ole, Husby, Frank, Berg Haugen.
2006
“A Tool for Converting from MARC to FRBR.”
16.
[journal]
Carlyle, Allyson, Sara, Ranger, Joel, Summerlin.
“Making the Pieces Fit: little Women, Works, and the Pursuit of Quality.”
17. [other] Chang, Naicheng, Yuchin, Tsai. “FRBRisation of Koha in the Context of CMARC: a UNIMARC-derived F ormat.” 77th IFLA General Conference and Assembly. [Conference paper] 1 - 15
18.
[journal]
Chang, Naicheng, Chang, Naicheng.
2013
“Experimenting with implementing FRBR in a Chinese Koha system.”
![]()
19.
[journal]
Cho, Jane.
2006
“A Study on the Application Method of the Functional Requirements for Bibliographic Records (FRBR) to the Online Public Access Catalog (OPAC) in Korean Libraries,”
![]()
20.
[web]
21.
[book]
Hickey, Thomas B., Jenny, Toves.
2009
22.
[journal]
Hickey, T.B., O’Neill., E.T..
2005
“FRBRizing OCLC's WorldCat.”
![]()
23.
[journal]
Hickey, Thomas B, Edward., T. O’Neill, Jenny, Toves.
2002
“Experiments with the IFLA Functional Requirements for Bibliographic Records (FRBR).”
24.
[book]
2010
25.
[web]
26.
[web]
27.
[journal]
O’Neill, Edward T..
2002
“FRBR: Functional Requirements for Bibliographic Records Application of the Entity-Relationship Model to Humphry Clinker.”
![]()
28.
[journal]
Rajapatirana, Bemal, Roxanne, Missingham.
2005
“The Australian National Bibliographic Database and the Functional Requirements for the Bibliographic Database (FRBR).”
![]()
29.
[journal]
Yee, Martha M..
“FRBRization: a Method for Turning Online Public Finding Lists into Online Public Catalogs.”
30.
[book]
Zhang, Yin, Athena, Salaba.
2009
31.
[journal]
Cho, Jane.
2004
“Study on the FRBR Algorithm and Application of KORMARC Database.”
![]()
32.
[journal]
Cho, Jane.
2005
“The Study on the FRBR Adoption into Cataloging Rule Focused on its Expression Level.”
![]()
33.
[journal]
Kim, Hyun-Hee, Yoo, Yeong-Jun, Park, Suh-Eun.
2007
“An Experimental Study on the FRBR Model Adaptation to KORMARC Database : Focusing on Music Materials.”
![]()
![]()
34.
[journal]
Kim, Jeong-Hyen.
2007
“An Analysis on the Work Types of Korean Books Based Bibliographical Relationship.”
![]()
![]()
35.
[journal]
Kim, Jeong-Hyen.
2007
“A Study on the Utility of FRBR Model in Korean Bibliographic Record.”
![]()
36.
[thesis]
Lee, Mihwa.
2008
37.
[thesis]
Lee, Sung-Sook.
2004
38.
[journal]
Lee, Sung-Sook.
2006
“A Study on the Application Strategies of the FRBR Model.”
![]()
39.
[journal]
Lee, You-Jeong.
2007
“A Study on Creation of MARC Record for FRBR Implementation.”
![]()
![]()
40.
[journal]
Rho, Jee-Hyun.
2008
“An Application of FRBR Model to KORMARC Records.”
![]()
![]()

