Journal of Korean Library and Information Science Society 2024 KCI Impact Factor : 0.91
-
pISSN : 2466-2542 / eISSN : 3140-2291
- https://journal.kci.go.kr/liss
pISSN : 2466-2542 / eISSN : 3140-2291
Fusion Approach to Targeted Opinion Detection in Blogosphere
1경북대학교
Blogs (short for Web logs), which are journal-like Web pages that started out as online diaries over a decade ago, have evolved in recent years to become one of the mainstream tools for collaborative content creation on the Web. Among the many characteristics of the blog, perhaps the most distinguishing is its highly personalized nature, often containing personal feelings, perspectives, and opinions about a topic. The blogosphere, with its rich collection of commentaries, is an important source for public opinion. However, finding “opinionated” blogs on a specific target (e.g., product, event, etc.) is a difficult task with compound challenges of Web search and opinion mining.
Even if topically relevant blogs were to be retrieved, identifying opinionated posts among them can be quite challenging due to the context-dependent nature of the subjective language. According to
This paper presents our approach to finding opinionated blogs, which consists of first applying traditional information retrieval (IR) methods to retrieve blogs about a given topic and then boosting the ranks of opinionated blogs based on the opinion scores generated by multiple assessment methods. The central idea underlying our opinion detection method, which is to rely on a variety of complementary evidences rather than trying to optimize a single approach, is motivated by our past experience that suggested that neither the lexicon-based approach nor the machine learning approach is well-suited for the blog opinion retrieval task (Yang et al. 2006;
The first group of studies we review comes from a body of work that explores methods of detecting opinions or sentiments in documents. Among the rich spectrum of literature in this area, we select a few that are relevant to opinion mining in blogosphere.
By using text analysis and external knowledge (i.e. Amazon’s Web Services for locating products),
Following a similar research direction,
Others investigated the lexicon-based sentiment detection method, where a dictionary of sentiment words and phrases with associated strength and orientation of sentiment is used to compute a sentiment score of documents
The content characteristics of blogs, namely the high level of non-posting content generated by blogware or spamming and non-standard usage of language often imbued with the informal tone of bloggers, pose new challenges for conventional opinion detection strategies that make use of syntactic cues in formal discourses or standard text analysis leveraging high frequency patterns.
Text Retrieval Conference (TREC), an international research forum that supports a variety of cutting-edge IR research, initiated the exploration of blog opinion mining in one of its specialized venues called the Blog Track in 2006 (Blog06), where methods that "uncover the public sentiment towards a given entity/target" in blogosphere were investigated. In 2009, the Blog Track introduced new search tasks of faceted blog distillation and top story identification with a new test collection (Blog08) but the revamped block track was soon replaced with Microblog Track that deals with searching microblogs such as Twitter in 2011
To find opinionated blogs on a given topic, most TREC participants employed a two-stage approach that involves an initial step of retrieving topically relevant blogs followed by a re-ranking step leveraging opinion finding features
Having explored the topical search problem over the years
• Opinion Lexicon: One obvious source of opinion is a set of terms often used in expressing opinions (e.g., “Skype
• Opinion Collocations: One of the contextual evidence of opinion comes from collocations used to mark adjacent statements as opinions (e.g., “
• Opinion Morphology: When expressing strong opinions or perspectives, people often use morphed word form for emphasis (“Skype is
Because blogs are generated by content management software (i.e. blogware), which allows authors to create and update contents via a browser-based interface, they are laden with non-posting content for navigation, advertisement, and formatting display. Therefore, the question of how such blogware-generated noise influences opinion detection merits consideration. In investigating the blog noise question, however, we did not include spam detection so as to determine whether the high noise level typical of blogs has adverse influence on opinion detection performance.
Our topical retrieval strategy in the blog track was driven by the hypothesis that query should be broad to ensure high recall. This strategy, which was realized in the form of minimal query processing without any query expansion, turned out to be a double-edged sword that worked well for longer queries that include more complete description of information need but performed poorly with short queries. To address the weakness of our past topical retrieval strategy, we extend our initial hypothesis as follows: “query should be broad yet descriptive enough to ensure high recall.” In accordance with the amended hypothesis regarding topical retrieval, the follow-up study reported in the paper investigated various Web-based query expansion methods to increase the initial retrieval performance for the short query.
Our opinion detection strategy is shaped by the hypothesis that there are multiple sources of opinion evidence that complement one another. Conventional opinion detection methods look to the most obvious source of the opinion evidence, namely the set of terms commonly used to express opinions (e.g., “Skype sucks”, “Skype rocks”, “Skype is cool”). The standard opinion terminology, or Opinion Lexicon as we call it, occurs frequently in opinionated documents while occurring infrequently in non-opinionated documents. Another source of opinion evidence that lies at the opposite end of the spectrum is what we call Opinion Morphology, which consists of morphed word forms used to express strong opinions or perspectives. The opinion morphologies, taking the form of compound word (e.g., “Skype is metacool”), repeated characters (e.g., “Skype is soooo buggy”), or intentional misspellings (e.g., “I luv Skype”), are creative expressions with low occurrence frequencies, which were found to be useful clues for sentiment detection
As for the association of opinion to its intended target, we hypothesize that the proximity of opinion expression to the target in question can serve as a reasonable surrogate for more complex syntactic analysis of natural language processing techniques. Since we do not apply any anaphor resolution, we believe that proximity scores should be supplemented with non-proximity scores for completeness.
Last but certainly not least, the fusion hypothesis underlies various layers of our approach, from query expansion and topical retrieval to opinion detection and system optimization. The fusion hypothesis, which posits that the whole is greater than sum of its parts, regards the state of “individual weaknesses” and “complementary strengths” as an ideal condition for fusion
Our approach to targeted opinion detection consists of a two-step process: a topical retrieval process and an opinion detection process. The topical retrieval component reranks an initial topic search for rank optimization to distill documents about a target topic at top ranks, after which the opinion scores are computed by multiple opinion scoring modules that leverage different sources of opinion evidence to maximize the coverage of opinion expressions. In a prior study, we implemented
<Fig. 1>. Targeted Opinion Detection System Architecture
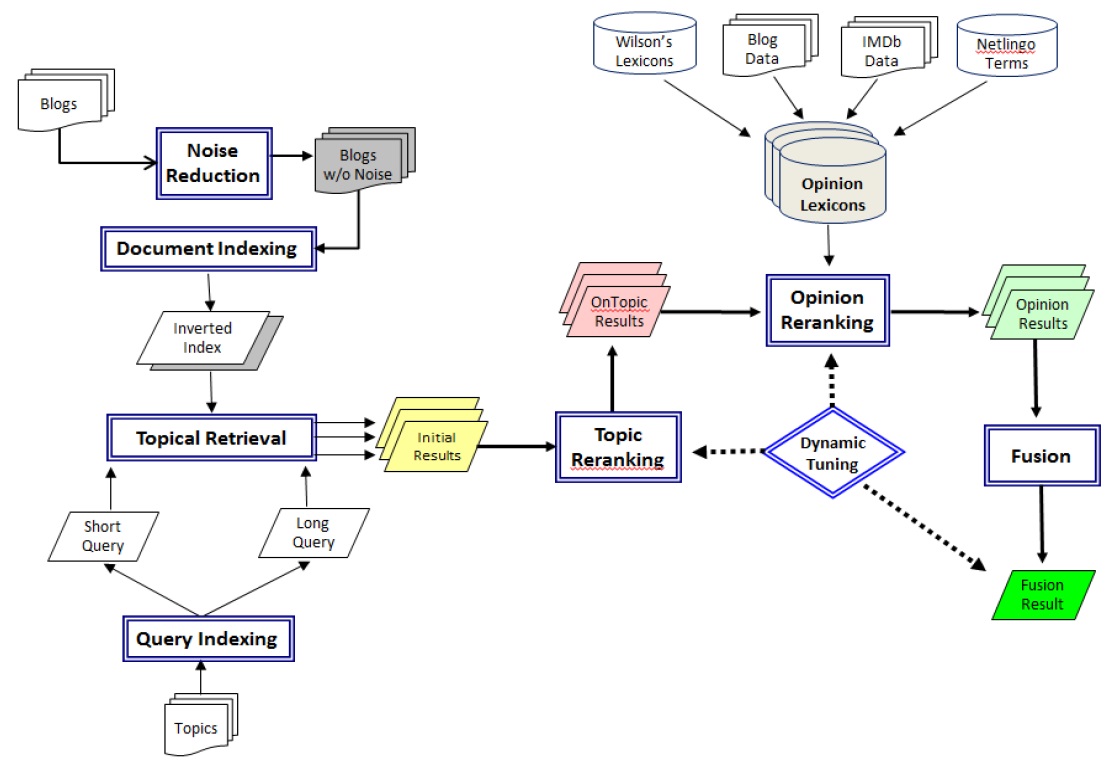
The blogosphere contains three types of noise: spam for the purpose of link farming or advertisement
To identify non-English (NE) blogs, we first made use of the language tags in blog feeds.
The basic heuristic of the NE token method, which is to flag a blog with a large proportion of NE tokens as a NE document, was refined iteratively by examining the results of the method to eliminate false positives (e.g., English blogs with NE tokens) and reduce false negatives (e.g., NE blogs with English tokens). The final version of the NE token method considers additional factors, such as the frequency and proportion of stopwords and document length, to accommodate NE blogs with English tokens and English blogs with NE tokens.
A blog contains blogware-generated content for navigation, advertisement, and display formatting as well as user-authored content of original posting and follow-up comments, all of which are delineated by markup tags. Unfortunately, non-standard use of different markup tags adopted by different blogwares makes tag-based exclusion of non-posting content (NPC) a rather challenging task. Our approach to NPC exclusion is to extract blog segments based on content-bearing markup tags first to prevent inadvertent exclusion of true content and then to apply noise exclusion to the remaining text based on “noise” tags. Since the tags come in all shapes and sizes and can contain various attributes (e.g., <!—maincontentsarea-->, <div class=”content_photowhite” id=”maincontent-block”>, <td id=”main_content” width=”466”>, <td class=”sidebar” rowspan=5>, <span class=”footer”>), we constructed regular expressions to identify content and noise tags as described below.
1. Extract all unique tag patterns from blogs.
2. Rank the tags by their occurrence frequency.
3. Examine the top k tags to compile a list of content and noise tags.
4. Construct regular expressions (regex) to identify the tags in the list.
5. Apply regex to the unique tag set.
6. Refine regex based on the examination of the regex results.
7. Repeat steps 5 & 6 until noise regex produces no false positives (i.e., no real content is excluded) and the majority of high frequency tags are matched by the regex.
Optimizing the ranking of the initial retrieval results is important for two reasons. First, on-topic retrieval optimization is an effective strategy for incorporating topical clues not considered in initial retrieval (Yang & Albertson 2004;
Our on-topic retrieval optimization involves reranking of the initial retrieval results based on a set of topic-related reranking factors, where the reranking factors consist of topical clues not used in initial ranking of documents. The topic reranking factors used the study are: Exact Match, which is the frequency of exact query string occurrence in document, Proximity Match, which is the frequency of padded
1. Compute topic reranking scores for top N results.
2. Partition the top N results into reranking groups based on the original ranking and a combination of the most influential reranking factors. The purpose of reranking groups is to prevent excessive influence of reranking by preserving the effect of key ranking factors.
3. Rerank the initial retrieval results within reranking groups by the combined reranking score.
The objective of reranking is to float low ranking relevant documents to the top ranks based on post-retrieval analysis of reranking factors. Although reranking does not retrieve any new relevant documents (i.e. no recall improvement), it can produce high precision improvement via post-retrieval compensation (e.g. phrase matching). The key questions for reranking are what reranking factors to consider and how to combine individual reranking factors to optimize the reranking effect. The selection of reranking factors depends largely on the initial retrieval method since reranking is designed to supplement the initial retrieval. The fusion of the reranking factors can be implemented by a weighted sum of reranking scores, where the weights represent the contributions of individual factors. The weighted sum method is discussed in more detail in the fusion section of the methodology.
Determining whether a document contains an opinion is somewhat different from classifying a document as opinionated. The latter, which usually involves supervised machine learning, depends on the document’s overall characteristic (e.g., degree of subjectivity), whereas the former, which often entails the use of opinion lexicons, is based on the detection of opinion evidence. At the sentence or paragraph level, however, the distinction between the two becomes inconsequential since the overall characteristic is strongly influenced by the presence of opinion evidence.
For opinion mining, which involves opinion detection rather than opinion classification, opinion assessment methods are best applied at subdocument (e.g., sentence or paragraph) level. At subdocument level, the challenges of machine learning approach are compounded with two new problems: First, the training data with document-level labels is likely to produce a classifier not well suited for subdocument level classification. Second, the sparsity of features in short “documents” will diminish the classifier’s effectiveness. The opinion detection challenge for machine learning was showcased in the TREC blog track, where machine learning approaches to the opinion finding task met with only marginal success
Our opinion detection approach, which is entirely lexicon-based to avoid the pitfalls of the machine learning problems, relies on a set of opinion lexicons that leverage various evidences of opinion. The key idea underlying our method is to combine a set of complementary evidences rather than trying to optimize the utilization of a single source of evidence. In keeping with the main research question of the study, we leveraged the complementary opinion evidences of
Opinion scoring modules used in this study are

where
Topic reranking for on-topic retrieval optimization and opinion reranking for opinion detection generate multitudes of reranking scores that need to be combined. Two most common fusion methods are
In our investigations


In reranking, the original scores should be combined with fusion scores of reranking factors in a way that enables the documents with high reranking factors to float to the top without unduly influencing the existing document ranking. This reranking strategy can be expressed as

where
To optimize the reranking formulas, which involves determination of fusion weights (
1) WIDIT (Web Information Discovery Integrated Tool,
2) A blog feed contains a summary list of blog entries (i.e., permalinks).
3) “Padded” query string is a query string with up to k number of words in between query words.
4) Non-rel Match is used to suppress the document rankings, while other reranking factors are used to boost the rankings.
We tested our targeted opinion detection approach with TREC’s Blog06 corpus, 50 topics (Topic 901-950) that describe the information needs for the opinion finding task, and associated relevance judgments. By first applying topic reranking to initial retrieval results and then applying opinion reranking, we generated a result set of 1000 blogs for each topic, which were evaluated and analysed to assess the effectiveness of our methodology.
The Blog06 corpus includes a crawl of feeds (XML), associated permalinks (blog postings in HTML), and feed homepages captured from December 2005 through February 2006. Among the blog document set of 100,649 feeds (39GB), 3.2 million permalinks (89GB), and 325,000 homepages (21GB), only the permalinks were judged for relevance in the opinion finding task. TREC assessed a pool of unique results created from merging top ranked blogs from submitted results. To be considered relevant, a blog had to be on topic and contain an explicit expression of opinion or sentiment about the topic, showing some personal attitude either for or against. Each of 50 test topics, which were constructed by TREC using queries from commercial blog search engines (e.g., BlogPulse and Technorati), consists of title (phrase), description (sentence), and narrative (paragraph) fields. For our study, we generated short queries from the title field and long queries from all three fields. An example of the TREC blog topic is shown in
<Fig. 2>. Topic 922 of TREC Blog track Opinion Finding task

The main performance evaluation metric used in the study is mean average precision (MAP), which is the average precision averaged over all topics. The average precision, which is computed by averaging the precision values obtained after each relevant document is retrieved, is a single-valued measure that considers both recall and precision to gauge the overall performance. Mean R-precision (MRP), which is the precision at rank R (total number of relevant items) averaged over topics, and precision at rank N (P@N) were also used to evaluate the system performances. Mean R-accuracy, which is the fraction of retrieved documents above rank R that are correctly classified averaged over topics, is used for evaluating polarity subtask results. R-precision and R-accuracy are measures that aim to produce more robust cross-system evaluations by dampening the effects of exact document rankings and variance of R across topics.
As described in the methodology section, our approach to targeted opinion detection combined topic reranking to optimize the on-topic retrieval, opinion reranking to integrate opinion detection into on-topic retrieval, and fusion at various levels to affect the complementary combination of multiple methods as well as sources of evidence.
The feed language tag method of our NE identification module flagged 16,121 blog permalinks while the NE token method flagged 334,219 permalinks as non-English documents. The result of NE identification was validated by an exhaustive review of 2,304 documents flagged as NE in the 2006 relevance judgments, which found only 3 false positives of little consequence (blogs with empty or gibberish content). The review also revealed 21 documents that were judged as topically relevant and 3 that were judged as opinionated, all of which appeared to be non-English documents that constitute potential errors in the relevance judgment file.
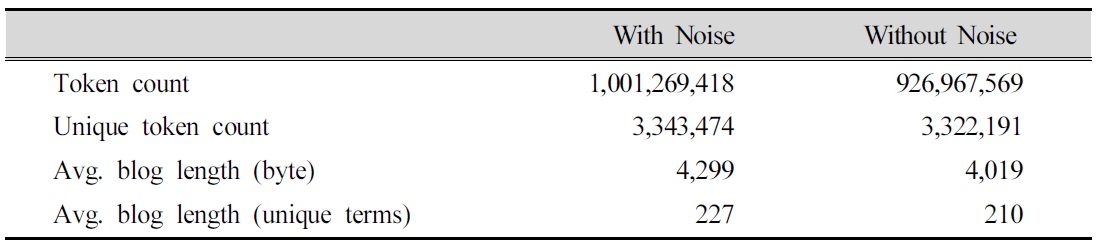
While NE identification excluded 12% of the blog permalinks, non-posting content (NPC) exclusion reduced noise levels in over 50% of the permalinks, where the average length reduction was 551 bytes. Overall, 74.3 million (7.4 %) tokens were excluded by NPC method. In terms of unique tokens, the NPC exclusion amounted to 21,283 (0.6 %) terms, which suggests the existence of common noise patterns.
<Tab. 1>. Blog Permalink Statistics before and after Noise Reduction
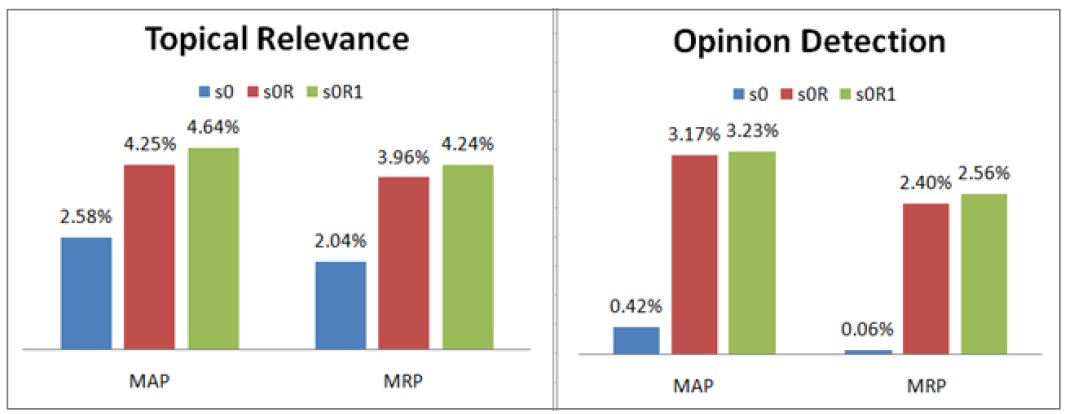
In order to isolate the effect of noise reduction on system performance, we examined the performance differences between retrieval run pairs that are identical in all aspects except for noise reduction.
<Fig. 3>. Noise Reduction Effects
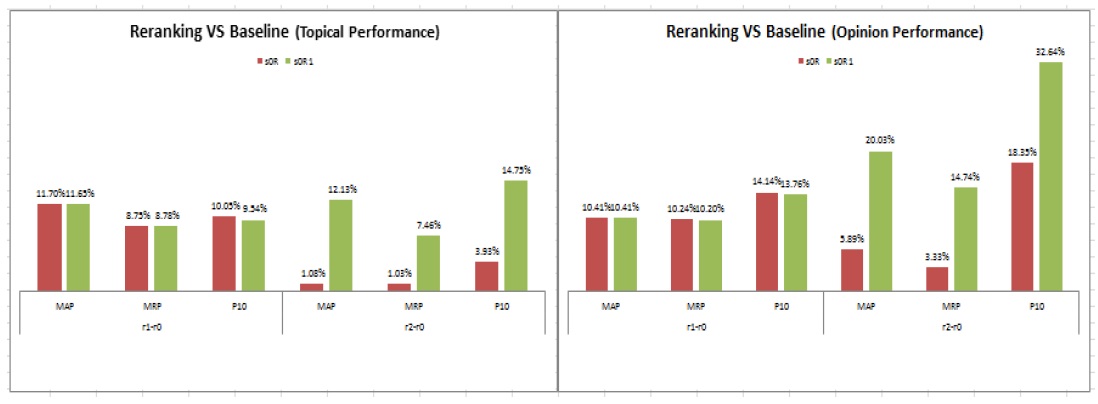
<Fig. 4>. Dynamic Tuning Effect
<Tab. 2>. Topic MAP

<Tab. 3>. Opinion MAP

Numbers in Tables 2 and 3 indicate that both topic and opinion reranking strategies are working as intended. Topic reranking effectively improves the on-topic retrieval performance of the baseline retrieval (10.0% for short and 8.7% for long query), after which opinion reranking boosts the o1pinion finding performance even more strongly (12.7% and 13.0%). It is interesting to note that the op_MAP improvements by topic rereanking are only about half of tp_MAP improvements (4.7% vs. 10.0% for short and 5.9% vs. 8.7% for long query) and tp_MAP improvements by opinion reranking are less than half of op_improvements (5.6% vs. 12.7%, 6.0% vs. 13.0%). This suggests that the relationship between topical and opinion relevance is not strictly linear. Topical relevance and opinion relevance may be correlated but the degree of topical relevance and the degree of opinion relevance may not be. In other words, a topically relevant document is more likely to contain opinions about the topic than topically irrelevant documents but a high ranking topically relevant document is not necessarily more likely to be opinionated than low ranking topically relevant documents.
Fusion of reranked documents, on the other hand, affects only marginal performance improvements. The improvements by fusion over the best non-fusion results are 5.6% tp_MAP for topic reranking and 1.2% op_MAP for opinion reranking. Possible explanations for the muted effect of fusion are: one, we did not engage in dynamic tuning to optimize the fusion formula as were done with reranking formulas; two, reranking produced near-optimal results with implicit fusion of reranking factors, thus leaving less room for improvement by explicit fusion of reranked results.
<Tab. 4>. Relative Short Query Perf ormance of WIDIT Opinion Finding System

<Tab. 5>. Improvements over Baseline for Short Query

Opinion detection performances of all TREC-2007 participants are shown in
<Fig. 5>. Opinion Detection Performances of TREC participants
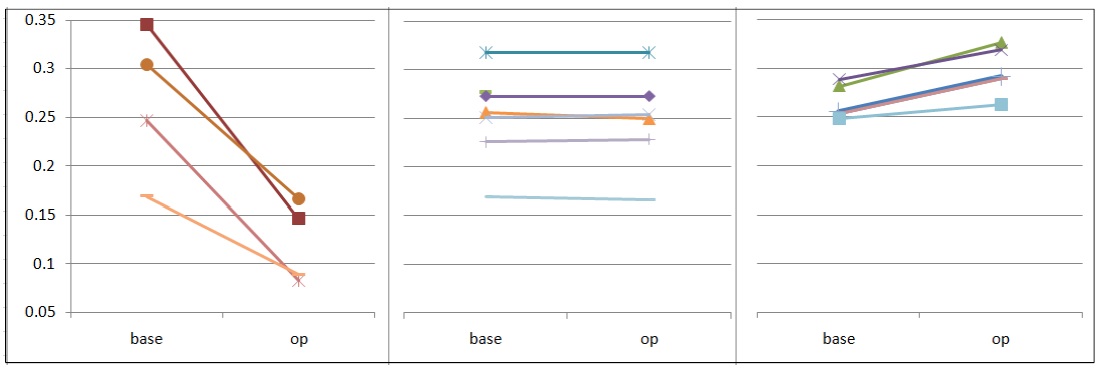
5) WIDIT in Tables 4 and 5 refers to our old system used in TREC-2007 participation.
6) The baseline performance of UIUC is unknown since they did not submit a baseline run.
In this paper, we presented a fusion approach to finding opinionate blogs on a given target. Our approach to finding opinionated blogs on target consists of first generating a good topical search result and then boosting the ranks of opinionated documents. On-topic retrieval optimization considers topical factors not utilized in the initial search to increase precision in the topical retrieval result, after which the opinion evidences in documents are leveraged to optimize the ranks of opinionated documents. Both on-topic retrieval optimization and opinion detection involve reranking of documents based on the combination of multiple reranking factors. In combining reranking factors, we used a weighted sum formula in conjunction with a reranking heuristic that are iteratively tuned via an interactive system optimization process called Dynamic Tuning.
Our opinion finding system in TREC-2006 blog track produced the best result among participants, but our results in TREC-2007 dropped to the 8th rank for the short query. We attribute our mediocre performance in the short query category in 2007 to the poor baseline result, which was at rank 10 among participants. In this study, we refined our noise reduction module to short queries to improve the baseline performance and extended our 2007 opinion module by combining the manual lexicon weights with probabilistic weights, and experimenting with distance-based scoring formula, all of which increased our short query performance by 13% (from .2894 to 0.3271) to move up to the rank 3.
Our experimental results, which were produced by applying our targeted opinion detection system in a standardized environment of TREC, clearly demonstrated the effectiveness of combining multiple complementary lexicon-based methods for opinion detection. The analysis of the results also revealed that Dynamic Tuning is a useful mechanism for fusion, and post-retrieval reranking is an effective way to integrate topical retrieval and opinion detection as well as to optimize the baseline result by considering factors not used in the initial retrieval stage. In comparison to top TREC blog track systems, our targeted opinion detection approach performed not only competitive but also quite effective in leveraging opinion evidences to improve the baseline performance.
1. [other] Lada, Adamic, Glance, N.. “The political blogosphere and the 2004 US election: Divided they blog.” Proceedings of the 3rd International Workshop on Link discovery 36 - 43
2. [other] Bartell, Brian T., Cottrell, G. W., Belew, R. K.. “Automatic combination of multiple ranked retrieval systems.” Proceedings of the ACM SIGIR Conference on Research and Development in Information Retrieval 173 - 181
3. [other] Chklovski, Timothy. “Deriving quantitative overviews of free text assessments on the web.” Proceedings of the 11th International Conference on Intelligent User Interfaces 155 - 162
4. [other] Ding, Xiaowen, Liu, B., Yu, P. S.. A holistic lexicon-based approach to opinion mining. Proceedings of the 2008 International Conference on Web Search and Data Mining 231 - 240
5. [other] Efron, Miles. “The liberal media and right-wing conspiracies: using cocitation information to estimate political orientation in web documents.” Proceedings of the 13th ACM International Conference on Information and Knowledge Management 390 - 398
6. [other] Fox, Edward A., Shaw, J. A.. “Combination of multiple searches.” Proceeding of the 3rd Text Retrieval Conference 105 - 108
7. [other] Hu, Minqing, Liu, B.. “Mining and Summarizing Customer Reviews.” In KDD’04: Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 168 - 177
8. [other] Joshi, Hemant, Bayrak, C., Xu, X.. “UALR at TREC: Blog Track.” Proceedings of the 15th Text Retrieval Conference
9. [other] Lee, Joon H.. “Analyses of multiple evidence combination.” Proceedings of the ACM SIGIR Conference on Research and Development in Information Retrieval 267 - 276
10. [other] Liu, Bing, Hu, M., Cheng, J.. “Opinion observer: analyzing and comparing opinions on the web.” Proceedings of the 14th International Conference on World Wide Web 342 - 351
11.
[journal]
Liu, Bing.
2012
Sentiment analysis and opinion mining.
![]()
12.
[journal]
Macdonald, Craig, Santos, R. L., Ounis, I., Soboroff, I..
2010
Blog track research at TREC.
![]()
13. [other] Mishne, Gilad. “Multiple Ranking Strategies for Opinion Retrieval in Blogs.” Proceedings of the 15th Text Retrieval Conference
14. [other] Mishne, Gilad, de Rijke, M.. “Deriving wishlists from blogs: Show us your blog, and we’ll tell you what books to buy.” Proceedings of the 15th International World Wide Web Conference 925 - 926
15. [other] Oard, Doug, Elsayed, T., Wang, J., Wu, Y., Zhang, P., Abels, E., Lin, D.. “TREC 2006 at Maryland: Blog, Enterprise, Legal and QA Tracks.” Proceedings of the 15th Text Retrieval Conference
16. [other] Ounis, Iadh, Macdonald, C., Lin, J., Soboroff, I.. Overview of the TREC-2011 microblog track. Proceedings of the 20th Text Retrieval Conference (TREC 2011)
17. [other] Ounis, Iadh, Macdonald, C., de Rijke, M., Mishne, G.. “Overview of the TREC 2006 Blog Track.” Proceedings of the 15th Text Retrieval Conference
18.
[journal]
Taboada, Maite, Brooke, J., Tofiloski, M., Voll, K., Stede, M..
2011
Lexiconbased methods for sentiment analysis.
![]()
19.
[journal]
Thelwall, Mike, Buckley, K., Paltoglou, G..
2012
Sentiment strength detection for the social web.
![]()
20.
[journal]
Thelwall, Mike, Buckley, K., Paltoglou, G., Cai, D., Kappas, A..
2010
Sentiment strength detection in short informal text.
![]()
21.
[journal]
Wiebe, Janyce, Wilson, T., Bruce, R., Bell, M., Martin, M..
2004
“Learning subjective language.”
![]()
22. [other] Wilson, Theresa, Pierce, D. R., Wiebe, J.. “Identifying opinionated sentences.” Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology 33 - 34
23. [other] Yang, Kiduk. “Combining Text- and Link-based Retrieval Methods for Web IR.” Proceedings of the 10th Text Retrieval Conference 609 - 618
24. [other] Yang, Kiduk. WIDIT in TREC 2008 Blog Track: Leveraging Multiple Sources of Opinion Evidence. Proceedings of the 17th Text Retrieval Conference
25.
[journal]
Yang, Kiduk.
2014
Combining multiple sources of evidence to enhance Web search performance.
![]()
![]()
26.
[book]
Yang, Kiduk, Yu, N..
2005
“WIDIT: Fusion-based approach to Web search optimization.”
27. [other] Yang, Kiduk, Yu, N., Valerio, A., Zhang, H.. “WIDIT in TREC2006 Blog track.” Proceedings of the 15th Text Retrieval Conference
28. [other] Yang, Kiduk, Yu, N., Valerio, A., Zhang, H., Ke, W.. “Fusion approach to finding opinions in Blogsophere.” Proceedings of the 1st International Conference on Weblog and Social Media
29. [other] Yang, Kiduk, Yu, N., Wead, A., La Rowe, G., Li, Y. H., French, C., Lee, Y.. “WIDIT in TREC2004 Genomics, HARD, Robust, and Web tracks.” Proceedings of the 13th Text Retrieval Conference
30. [other] Yang, Kiduk, Yu, N., Zhang, H.. “WIDIT in TREC2007 Blog track: Combining lexicon-based methods to detect opinionated Blogs.” Proceedings of the 16th Text Retrieval Conference
31. [other] Zhang, Ethan, Zhang, Y.. “UCSC on TREC 2006 Blog Opinion Mining.” Proceedings of the 15th Text Retrieval Conference
32. [other] Zhang, Wei, Yu, C.. “UIC in TREC 2006 Blog Track.” Proceedings of the 15th Text Retrieval Conference

